
Supply Chain Data Sets: A Practical Guide for Logistics Leaders
- Logistics teams that trust their data move faster than those that verify it twice.
- Supplier master data is the most strategically valuable data set that most organizations underinvest in.
- Multi-tier visibility requires a data infrastructure that extends beyond contracts and into real-time supplier operations.
April 13, 2026 | Digital Supply Chain Transformation 7 minutes read
One of the most persistent pain points for procurement leaders today is making high-stakes decisions without reliable, real-time visibility into what is actually happening across their supply networks. Disruptions that once took weeks to surface now unfold in hours.
The solution to the growing gap between operational complexity and strategic clarity lies in purpose-built supply chain data sets. Global enterprises need structured, integrated repositories of logistics intelligence that give leaders the full picture, as events unfold.
Most leaders fumble when asked: What data are you actually collecting? How is it structured? Is it clean enough to trust? Even fewer understand that the real competitive advantage does not come from having data but from having the right data organized in a way that AI agents and advanced logistics analytics engines can actually act on.
Before looking for out-of-the-box AI tools, you first need the right data architecture strategy. This guide breaks down what supply chain data sets are and why they matter for enterprises that want to build a data-mature supply chain organization.
What Are Supply Chain Data Sets (And Why They Matter in Logistics)?
Supply chain data sets are structured collections of information that capture every meaningful event, transaction, and interaction across the end-to-end supply network from raw material sourcing and supplier performance to transportation routing, inventory positioning, and last-mile delivery.
For enterprise organizations operating at scale, managing hundreds of suppliers, multiple distribution centers, and complex demand variability makes the business case for structured supply chain data span far beyond operational efficiency.
Clean, integrated logistics data sets reduce working capital exposure by improving forecast accuracy and prevent costly disruptions by surfacing supplier risk signals earlier.
Do You Trust Your Supply Chain Data?
Strong data sets guide logistics decisions and supply chain strategy
Five Types of Supply Chain Data Sets for Logistics
To build a high-performing autonomous ecosystem, you must categorize your information into distinct, functional logistics data sets.
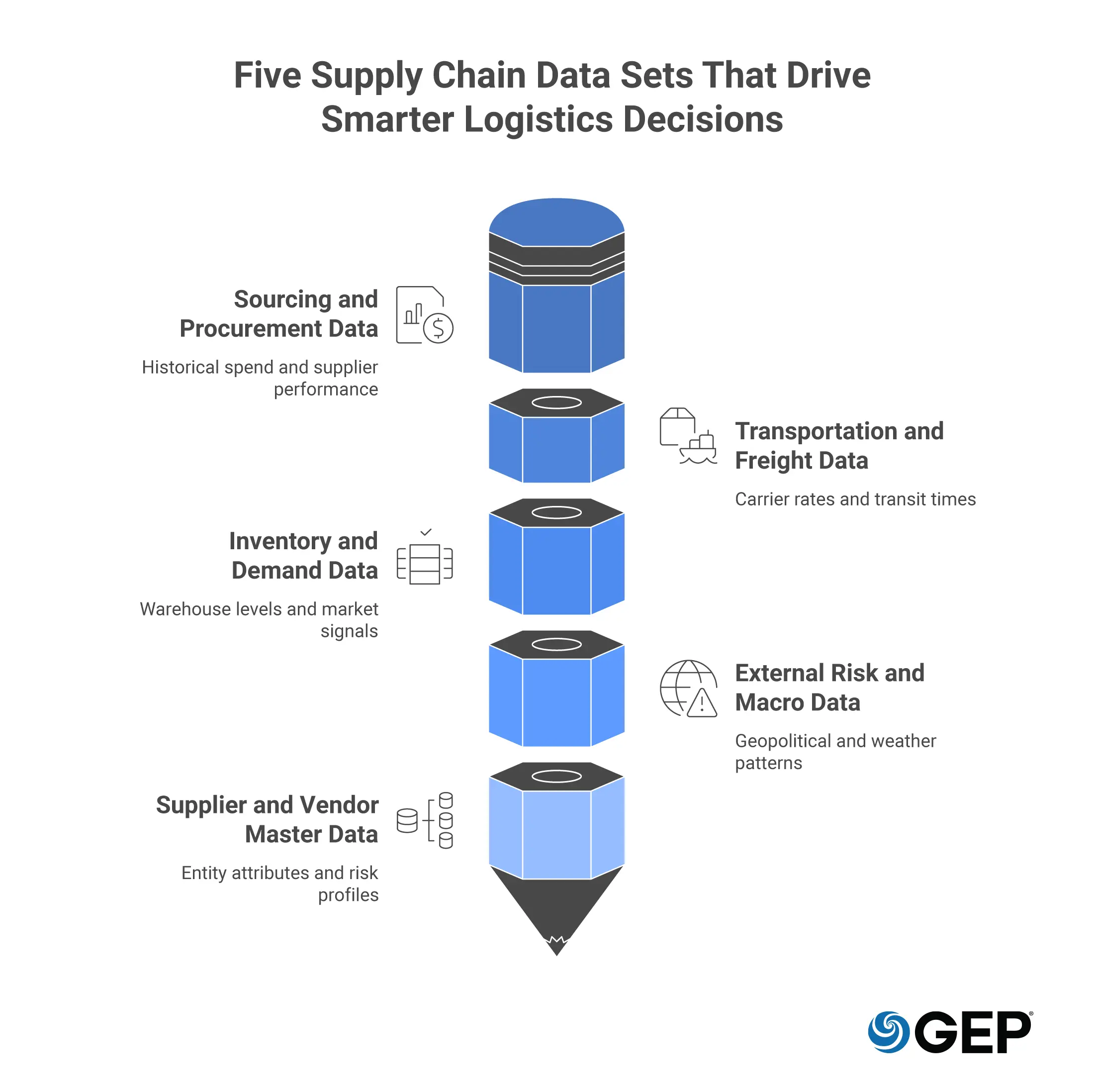
Understanding these categories allows you to deploy specific AI agents tailored to different segments of the value chain.
1. Sourcing and Procurement Data
This includes historical spend, supplier performance ratings, and contract terms. It is the fuel for supply chain analytics that identify where you are overpaying for tail spend or where a supplier’s financial health is beginning to wane.
2. Transportation and Freight Data
These data sets track carrier rates, transit times, fuel surcharges, and port congestion levels. This is where logistics analytics find hidden savings by optimizing routes and consolidating shipments in real time.
3. Inventory and Demand Data
By merging internal warehouse levels with external market demand signals, you create a dataset that prevents both stockouts and the bullwhip effect that leads to bloated inventory.
4. External Risk and Macro Data
This encompasses geopolitical signals, weather patterns, and ESG (Environmental, Social, and Governance) scores. It allows your system to sense black swan events before they crystallize.
5. Supplier and Vendor Master Data
This category captures the attributes, performance history, compliance status, financial health indicators, and risk profiles of every entity in your supply base. The supplier master data is arguably the most strategically valuable data set.
6 Key Components of Logistics Supply Chain Data Sets
The highest weightage in your digital transformation must be placed on the quality and granularity of your data components. Without high-integrity components, even the most advanced agentic AI will produce hallucinations or flawed strategies.
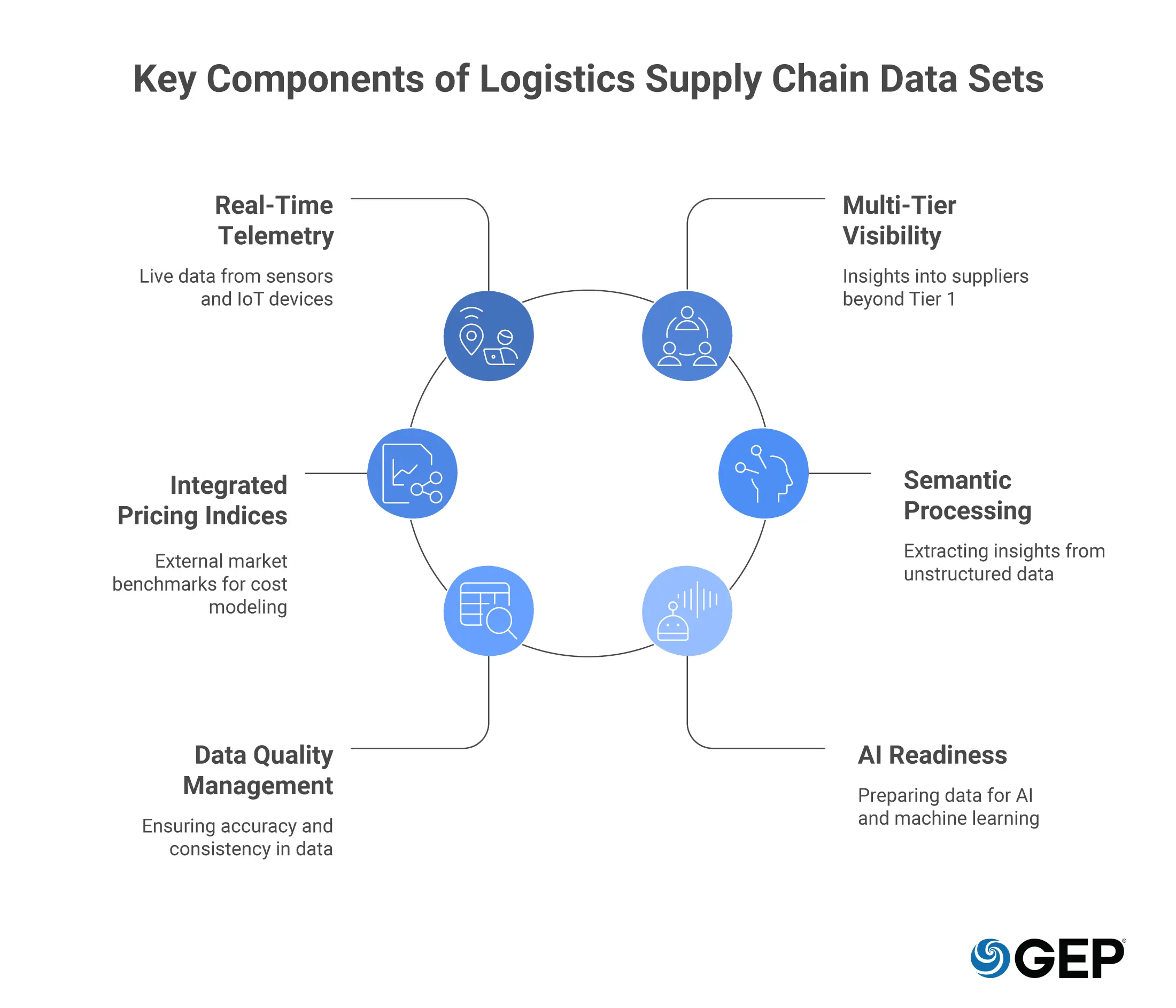
1. Real-Time Telemetry and IoT Integration
Modern logistics require live data. This means integrating GPS, temperature sensors, and RFID signals directly into your logistics data sets. When your data is live, your AI agents can perform predictive sensing, identifying that a shipment of perishables is at risk of spoilage due to a reefing failure and automatically triggering an insurance claim or a replacement order.
The most competitive supply chains are moving toward event-driven architectures where IoT sensors, carrier APIs, and supplier portals feed continuous event streams into the data layer. Real-time logistics data sets give your teams the ability to detect deviations as they happen and respond before the disruption escalates into a crisis.
2. Multi-Tier Supplier Visibility
You cannot manage what you cannot see. A key component of a robust dataset is visibility into Tier 2 and Tier 3 suppliers. Most intelligence gaps hide in the sub-tiers of your chain; capturing this data allows you to see when a fire at a specialized chemical plant in East Asia will affect your production six months down the line.
3. Integrated Pricing Indices
Your data must include external market benchmarks. By feeding real-time commodity and freight indices into your supply chain analytics engine, you enable should-cost modeling. This ensures that when the market price for raw materials drops, your procurement agents are immediately alerted to renegotiate contracts that are currently pegged to outdated, higher rates.
4. Semantic and Unstructured Data Processing
Not all valuable data fits into a neat row in a database. Modern executive teams are using Natural Language Processing (NLP) to pull insights from news feeds, PDF contracts, and even social media. Integrating this unstructured data into your core sets allows for a 360-degree view of the supply chain truth.
5. Data Quality Management
Completeness, accuracy, consistency, timeliness, and uniqueness are the five pillars of data quality. For supply chain data sets specifically, inconsistent unit-of-measure coding, duplicate supplier records, and incomplete transaction histories are among the most damaging quality issues.
Invest in automated data quality monitoring using rule-based engines or AI-driven anomaly detection. You’ll recover that investment quickly through avoided errors and greater confidence in decisions.
6. AI and Machine Learning Readiness
Modern supply chain analytics does not stop at reporting and visualization. The real frontier is predictive and prescriptive intelligence with features like demand forecasting, supplier risk scoring, dynamic safety-stock optimization, and autonomous procurement.
For AI and agentic AI models to operate effectively, the underlying data sets must be feature-rich, historically deep, and consistently labeled. Organizations building AI-powered supply chains need to engineer their data sets with model training and inference in mind.
Procurement And Supply Chains Need Agility
AI orchestration supports adaptive service delivery models
Common Challenges in Managing Supply Chain Data Sets
Even with the best intentions, the road to an agentic, data-driven supply chain is fraught with systemic hurdles. You must anticipate these five common challenges:
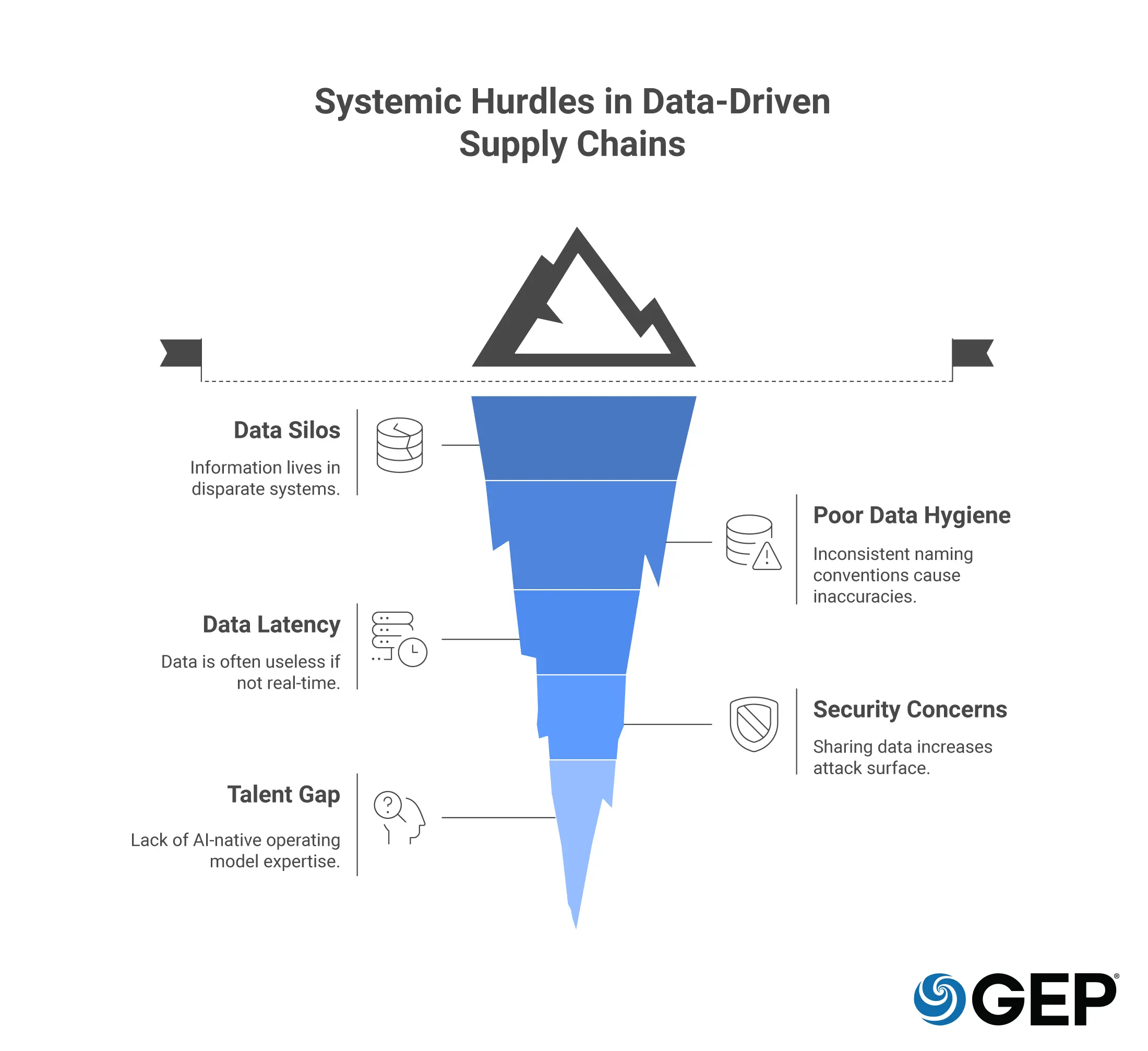
1. Data Silos and Fragmentation
Information often lives in disparate systems. Procurement has contracts, logistics has freight bills, and finance has payments. Without a unified data core, your intelligence gap remains wide.
2. Poor Data Hygiene
Inconsistent naming conventions can lead to massive inaccuracies in supply chain analytics, making it impossible to see total global spend with a single entity.
3. Latency and Stale Information
In a high-velocity market, data that is 24 hours old is often useless. Moving from batch processing to real-time streaming is a significant technical and cultural hurdle.
4. Security and Data Sovereignty
As you share data with more partners to achieve integration, you increase your attack surface. Managing who owns the data and how it is protected across borders is a top-tier executive concern.
5. The Talent Gap
Having the data is one thing; having a team that understands how to build AI-native operating models around that data is another. The shift from tactical buyer to data strategist requires a total rethink of your talent model.
Closing the Intelligence Gap and Reclaiming Your Growth
The future of procurement requires building a digital infrastructure in which information operates autonomously.
As you move toward an agentic model, your supply chain data sets become the nervous system of your organization, sensing threats and identifying opportunities with a speed that no human team can match. You are moving toward a world of autonomous commerce, where the machine handles the friction of the how so that you can focus on the where of your global strategy.
To lead in the next decade, you must stop viewing data as a record of the past and start viewing it as the blueprint for your future resilience. The organizations that win will be those that treat their supply chain management software as a strategic asset, constantly refined by real-time intelligence and executed with surgical precision.




FAQs
To improve quality, you must move toward automated data ingestion and away from manual entry. Implementing strict data governance protocols and using AI to perform continuous data cleansing ensures that your logistics data sets remain accurate. By identifying and merging duplicate records and validating addresses and tax IDs against global databases in real-time, you create a single version of the truth that supports high-level decision-making.
Detailed data sets allow for the transition from descriptive to prescriptive analytics. When you have a rich history of carrier performance and route volatility within your logistics analytics, your system can suggest the optimal path based on more than just cost. It can factor in carbon footprint, risk of delay, and historical reliability. This leads to reduced lead times, lower freight spend, and a significantly higher level of service for the end customer.
The most effective teams start with a business-first question rather than just collecting data for the sake of it. Focus on high-impact areas like contract leakage or unmanaged tail spend first. Ensure your supply chain data is accessible across the entire organization to break down silos, and prioritize interoperability by ensuring your data sets can speak to external supplier systems and global market feeds. Finally, treat your data as a living product that requires constant updates and strategic oversight from the C-suite.